
[Paper Review] Spann3R: Dense 3D Reconstruction with Spatial Memory

Introduction
In this post, I review Spann3R: Dense 3D Reconstruction from Ordered or Unordered Image Collections by Hengyi Wang and Lourdes Agapito (UCL), accepted to 3DV 2026.
If you have been following the recent paradigm shift in 3D vision, you are likely familiar with DUSt3R. It revolutionized the field by treating dense 3D reconstruction as a regression problem, completely bypassing the need for camera calibration or pose priors. However, DUSt3R has a significant bottleneck: it is fundamentally a pairwise method. To reconstruct a full scene, it requires an offline “Global Alignment” step that optimizes over a dense graph of image pairs (\(O(N^2)\) complexity), making it unsuitable for real-time applications.
Spann3R (Spatial Memory for 3D Reconstruction) solves this by repurposing the DUSt3R architecture into an incremental, online pipeline. By introducing a Spatial Memory system, it allows the network to “remember” previous geometry and regress pointmaps directly into a global coordinate system in a single forward pass (\(O(N)\) complexity).
Paper Info
- Title: 3D Reconstruction with Spatial Memory
- Authors: Hengyi Wang, Lourdes Agapito
- Affiliations: University College London (UCL)
- Conference: 3DV 2026
- Project Page: Spann3R Website
Background: The DUSt3R Bottleneck
DUSt3R operates by predicting the 3D pointmap for a pair of images \(I_1, I_2\). It outputs two pointmaps \(X_{1,1}, X_{2,1}\) both in the coordinate frame of \(I_1\).
While powerful, this approach has scaling issues:
- Quadratic Complexity: To be robust, you need to estimate geometry for many pairs (\(N \text{ images} \to \approx N^2 \text{ pairs}\)).
- Offline Optimization: You must gather all pairwise predictions and solve a global optimization problem to align them into a single world frame.
Spann3R asks: Can we keep the geometric priors of DUSt3R but deploy them sequentially like a SLAM system, without the heavy graph optimization?
Core Intuition: The “Spanner” Analogy
The authors liken their method to a mechanical spanner. Instead of building the whole structure at once, Spann3R tightens the geometry “on the fly.”
The core idea is Spatial Memory. In a standard Transformer, attention is computed over the current context. In Spann3R, the model maintains an external memory bank of previously reconstructed geometry. When a new frame arrives, the model queries this memory to determine where the new pixels lie in the global coordinate system, rather than just relative to the previous frame.
This transforms the problem from Pairwise Regression \(\to\) Sequence-to-Map Regression.
Methodology
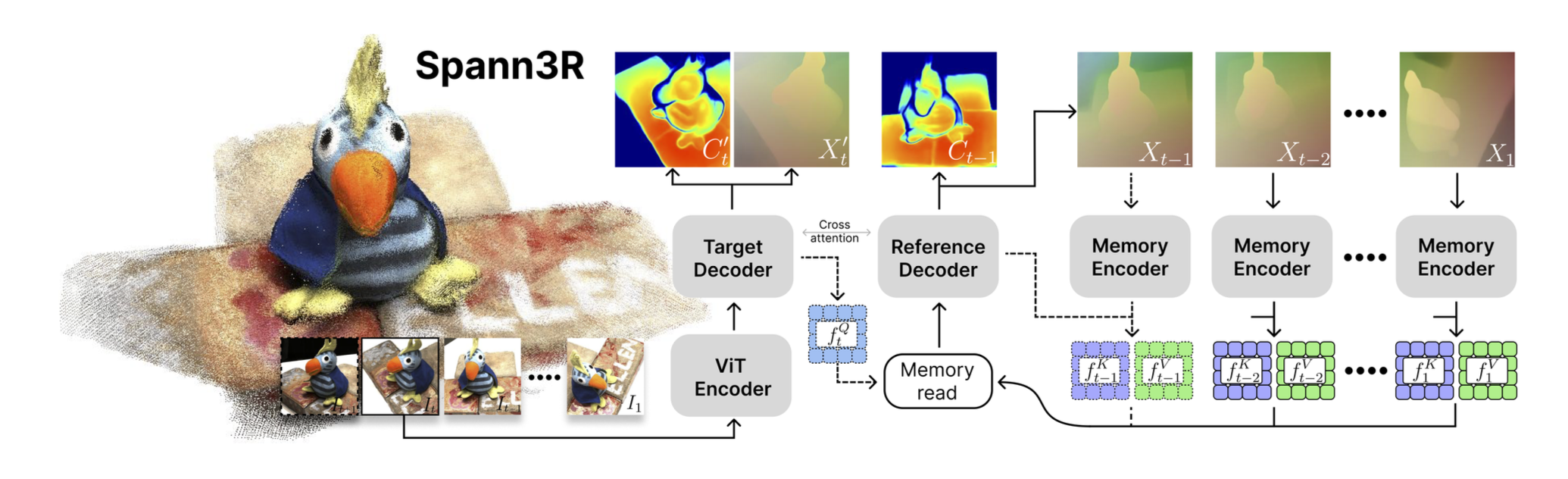
Spann3R cleverly repurposes the pre-trained weights of DUSt3R but changes the architectural flow to support memory interaction.
1. Repurposing the Decoders
Original DUSt3R has two identical decoders (Target & Reference). Spann3R specializes them:
- Target Decoder (Query Generator): Instead of predicting the second view’s geometry directly, it processes the current frame \(I_t\) to generate Query Features (\(f_Q\)). These features are used to search the memory bank.
- Reference Decoder (Geometry Predictor): Takes the Fused Features (\(f_G\), retrieved from memory) and predicts the final Pointmap (\(X_t\)) and Confidence (\(C_t\)).
2. Spatial Memory System
The memory is not just a buffer of past images; it is a structured key-value store designed for geometric reasoning.
- Memory Key (\(f_K\)): Encodes both Visual Appearance (from the image encoder) and Geometric Structure (from the previous depth prediction). This allows the model to query based on “what it looks like” and “where it is.”
- Memory Value (\(f_V\)): Stores the dense 3D information.
The retrieval is done via Cross-Attention: \(f_G^t = \text{Attention}(Q=f_Q^t, K=f_K, V=f_V)\)
3. Working vs. Long-Term Memory (X-Mem)
To handle long sequences without exploding GPU memory, Spann3R adopts a strategy from Video Object Segmentation (specifically X-Mem):
- Working Memory: Stores high-resolution features from the most recent 5 frames.
- Long-Term Memory: As frames age, they are compressed and moved here.
- Sparsification: The model tracks which memory tokens are frequently accessed (high attention weights). “Forgotten” tokens are pruned, keeping the memory footprint bounded regardless of sequence length.
Results
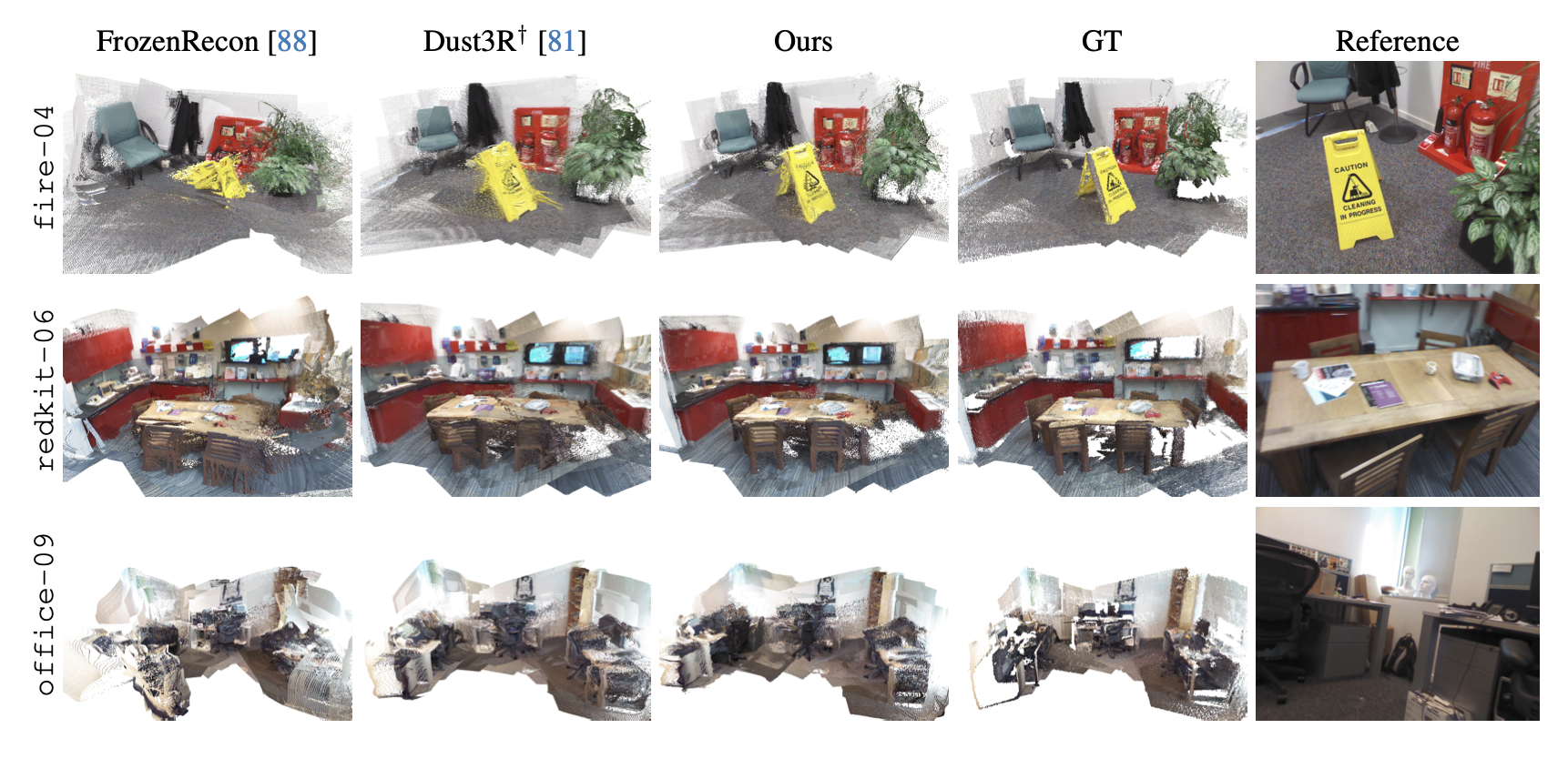
Spann3R was evaluated against DUSt3R (running in offline mode) and optimization-based methods like FrozenRecon.
Key Performance Metrics (ScanNet):
| Method | Mode | Accuracy \(\downarrow\) | Completion\(\downarrow\) | FPS |
|---|---|---|---|---|
| FrozenRecon | Offline (Opt) | 0.124 | 0.076 | <0.1 |
| DUSt3R (Full) | Offline (Opt) | 0.028 | 0.012 | 0.78 |
| Spann3R (Ours) | Online | 0.034 | 0.014 | 65.49 |
Qualitative Wins:
- Speed: It runs at ~65 FPS on an RTX 4090, compared to <1 FPS for DUSt3R.
- Global Consistency: Unlike simple visual odometry which drifts instantly, the Spatial Memory allows Spann3R to maintain scale and consistency over room-scale trajectories.
Limitations
- Drift in Large Loops: Because it is purely incremental and lacks a global Bundle Adjustment (BA) step, errors can accumulate in very large loops (e.g., walking around a whole building). The current memory system helps, but it is not a perfect substitute for loop closure optimization.
- Training Window: Due to GPU constraints, the model is trained on short clips (5 frames). While curriculum learning helps it generalize, it sometimes struggles with extremely long-term dependencies that exceed its training horizon.
Takeaways
Spann3R represents a logical evolution in the “Foundation Model for Geometry” era.
Key lessons:
- Regress Locally, Align Globally (via Memory): We don’t need explicit graph optimization to achieve global consistency. A well-structured memory bank can serve as a differentiable map.
- Repurposing Weights: It is impressive how the authors reused DUSt3R’s weights for a completely different architectural flow (Pairwise \(\to\) Sequential), saving massive training costs.
- The End of SfM? With models like this running at 60 FPS, the traditional feature-matching + bundle adjustment pipeline is looking increasingly obsolete for real-time applications.