
[Paper Review] DIFIX3D+: Improving 3D Reconstructions with Single-Step Diffusion Models

Introduction
In this post, I review “DIFIX3D+: Improving 3D Reconstructions with Single-Step Diffusion Models” at CVPR 2024 by Jay Zhangjie Wu et al. The paper proposes a single-step diffusion-based fixer DIFIX that (1) improves the 3D representation during training and (2) acts as a real-time post-render enhancer at inference. A single model works for both NeRF and 3D Gaussian Splatting (3DGS) backbones, targeting artifacts that appear in sparse coverage and extreme novel viewpoints.
Paper Info
- Title: DIFIX3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
- Authors: Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, Huan Ling
- Conference: CVPR 2025
- Project: NVIDIA Toronto AI (DIFIX3D)
Motivation
Even with strong reconstructors like NeRF and 3DGS, underconstrained regions (sparse views, pose noise, lighting inconsistencies) cause ghosting, spurious geometry, and missing regions, especially far from training poses. Per-scene optimization is also vulnerable to shape–radiance ambiguity. Large 2D diffusion models learn broad image priors, but repeatedly querying them during 3D optimization is slow and often object-centric. DIFIX3D+ asks: Can we adapt a fast, single-step image diffusion model to fix neural render artifacts and then distill those fixes back into 3D for multi-view consistency?
Core Idea (Pipeline at a Glance)
DIFIX3D+ uses a single-step diffusion model (SD-Turbo base) fine-tuned as an artifact fixer (DIFIX) with reference-mixing attention:
- Reconstruction-time distillation (DIFIX3D)
- Interpolate poses from reference → target, render pseudo novel views from the current 3D model.
- Apply DIFIX to clean artifacts.
- Distill cleaned images back into the 3D model.
- Progressively expand trajectory coverage with small pose perturbations (~every 1.5k steps), iterating until the target poses are well-conditioned.
- Inference-time enhancement (DIFIX3D+)
- After training, run DIFIX once per rendered frame as a real-time post-processor (~76 ms on A100).
This two-stage design yields consistent improvements in both pixel metrics and perceptual quality while remaining fast.
Background
NeRF volume rendering for a ray \(r(t)=\mathbf{o}+t\mathbf{d}\):
\(C = \sum_{i=1}^{N} \alpha_i\, \mathbf{c}_i \prod_{j<i}(1-\alpha_j),
\quad \alpha_i = 1 - \exp(-\sigma_i \,\delta_i).\)
3DGS replaces sampled points with Gaussians (mean \(\boldsymbol\mu_i\), covariance \(\boldsymbol\Sigma_i\), opacity \(\eta_i\)):
\(\alpha_i = \eta_i \exp\!\Big(-\tfrac{1}{2}(\mathbf{p}-\boldsymbol\mu_i)^\top \boldsymbol\Sigma_i^{-1}(\mathbf{p}-\boldsymbol\mu_i)\Big),\)
with \(\boldsymbol\Sigma = \mathbf{R}\mathbf{S}\mathbf{S}^\top \mathbf{R}^\top\).
Both yield artifacts when supervision is weak—precisely what DIFIX targets.
DIFIX: A Single-Step Diffusion Fixer
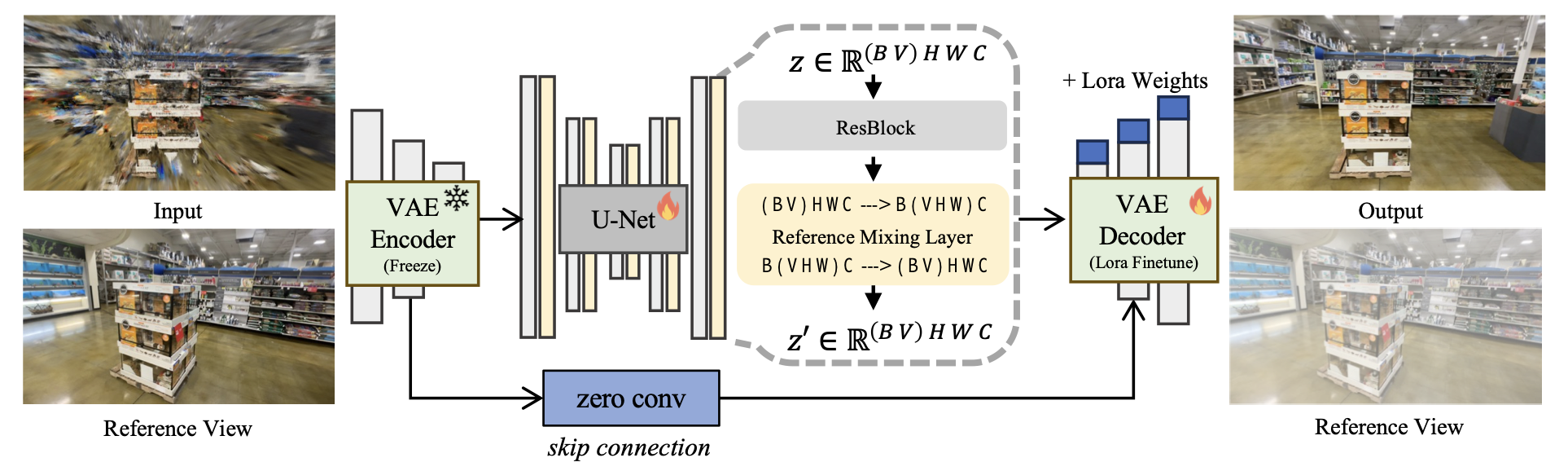
Backbone & conditioning. DIFIX starts from SD-Turbo and is turned into an image-to-image artifact remover with reference-mixing attention. Given a degraded render \(\tilde{I}\) and one (or few) reference views \(I_{\text{ref}}\), frames are encoded to latents \(z \in \mathbb{R}^{V\times C\times H\times W}\). A reference-mixing layer reshapes across the \((V,H,W)\) axes to perform attention over all views/spatial tokens, letting the model pull structure/texture cues from references while preserving the target view’s layout.
Noise level selection. Instead of the usual \(\tau{=}1000\), DIFIX uses \(\tau \approx 200\), matching the “artifact distribution” of neural renders to a single-step denoising that removes artifacts without hallucinating away scene content.
Losses. Trained with 2D supervision only: \(L = \underbrace{\| \hat{I}-I \|_2^2}_{L_{\text{Recon}}} + \underbrace{\text{LPIPS}(\hat{I}, I)}_{L_{\text{Percep}}} + \underbrace{0.5\,\sum_{\ell}\|\mathbf{G}_\ell(\hat{I})-\mathbf{G}_\ell(I)\|_2^2}_{L_{\text{Gram}}}\),
where \(\mathbf{G}_\ell(I)=\phi_\ell(I)^\top \phi_\ell(I)\) is the Gram matrix of VGG-16 features.
Data curation to simulate realistic artifacts and get paired (corrupted, clean) supervision:
- Sparse reconstruction (hold-out views),
- Cycle reconstruction (shift trajectory by ~1–6 m on driving data, render & swap),
- Cross-reference (multi-cam rigs; train on one cam, render others),
- Model underfitting (short schedules to amplify artifacts).
Progressive 3D Updates (DIFIX3D)
To avoid per-frame inconsistencies from pure post-processing, DIFIX outputs are distilled back into the 3D model with progressively expanding pose perturbations. Sketch:
- Train on reference views.
- Every ~1.5k iters: slightly perturb poses toward targets → render → DIFIX → add to training set.
- Repeat until coverage reaches target views.
This curriculum strengthens multi-view conditioning, taming flicker and stabilizing high-freq details.
Real-Time Post-Render (DIFIX3D+)
Even after distillation, tiny residual artifacts remain (capacity limits, supervision gaps). A final single-step pass of DIFIX at test time cleans them up in ~76 ms/frame (A100)—> practical for real-time or interactive viewers.
Results (Highlights)

- Backbones: Nerfacto (NeRF) and 3DGS both benefit.
- Benchmarks: DL3DV (in-the-wild), Nerfbusters (artifact stress-test), and an internal RDS automotive dataset.
- Gains (typical ranges reported):
- PSNR: ~+1 dB,
- FID: ~2–3× lower,
- LPIPS: consistently lower,
- Improved TSED (epipolar consistency) vs. baselines.
- Speed: Single-step inference enables >10× faster integration than methods that query diffusion every training step.
Importantly, one DIFIX model works for both NeRF and 3DGS artifact patterns.
Comparisons & Positioning
- Vs. NeRFLiX / reference aggregation: Deterministic enhancers help near references but blur/hallucinate under ambiguity. DIFIX adds generative priors while the distillation loop keeps multi-view consistency.
- Vs. diffusion-at-every-step: DIFIX3D+ avoids prohibitive slowdowns by batching diffusion calls into pseudo-view creation rounds + single-step inference.
- Vs. 3DGS-Enhancer / Deceptive-NeRF: Similar spirit (augment pseudo-views), but progressive pose curriculum and real-time post-render are key differentiators.
Limitations
- Dependent on the 3D base: If the reconstruction fails catastrophically (e.g., missing whole objects), DIFIX cannot conjure geometry.
- Prior bias: As a 2D prior, DIFIX may prefer plausible but dataset-typical textures/colors if supervision is extremely weak.
- Residual temporal jitter: Pure post-processing can flicker; the progressive distillation mitigates this, but extreme sparsity still challenges perfect coherence.
Practical Notes
- Plug-and-play: Works with Nerfstudio-style pipelines (Nerfacto) and modern gsplat renderers for 3DGS.
- Training: LoRA-style finetune (freeze VAE encoder; finetune decoder); reference-mixing attention layers are simple to drop in.
- Noise level: \(\tau \approx 200\) is the sweet spot—too high (\(600\text{–}1000\)) over-hallucinates; too low (\(\leq 10\)) under-fixes.
Conclusion
DIFIX3D+ shows that single-step diffusion can be a practical, general tool to fix neural render artifacts: distill cleaned pseudo-views to improve the 3D itself, then finish with a real-time enhancer at test time. The result is sharper, more consistent novel views across both NeRF and 3DGS, with strong perceptual gains at modest cost.