
[Paper Review] SANA: EFFICIENT HIGH-RESOLUTION IMAGE SYNTHESIS WITH LINEAR DIFFUSION TRANSFORMERS

Introduction
In this post, I review SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers by Enze Xie et al. (NVIDIA, MIT, Tsinghua), published at ICLR 2025.
SANA introduces a linear-time diffusion transformer capable of generating 4K images within seconds on consumer GPUs.
Instead of scaling model size like FLUX or SD3, it achieves efficiency through three pillars:
deep compression, linear attention, and LLM-based text conditioning.
The model rivals FLUX in quality with 20× fewer parameters and 100× faster inference.
Paper Info
- Title: SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
- Authors: Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, Song Han
- Affiliations: NVIDIA, MIT, Tsinghua University
- Conference: ICLR 2025
- Code: SANA (GitHub)
Background: From U-Nets to Linear Diffusion Transformers
Most text-to-image diffusion models such as Stable Diffusion 3, PixArt-Σ, or FLUX rely on U-Net denoisers with quadratic attention cost.
This limits scalability beyond 1K resolution and demands multi-billion parameter models.
SANA departs from this trend by replacing the U-Net with a Transformer-only denoiser optimized for O(N) complexity.
A deep-compression autoencoder (AE-F32C32) reduces latent token count by 16×, allowing real-time high-resolution diffusion.
Problem Definition
Given a text prompt \(p\) and latent noise \(\mathbf{z}_T\),
a diffusion model reconstructs an image \(\mathbf{x}_0\) through:
SANA learns a velocity-based denoising function \(v_\theta(\mathbf{z}_t, t, p)\) under the Rectified-Flow formulation:
\[\frac{d\mathbf{z}_t}{dt} = v_\theta(\mathbf{z}_t, t, p),\]allowing direct trajectory prediction between noise and clean latents for faster convergence.
Architecture Overview
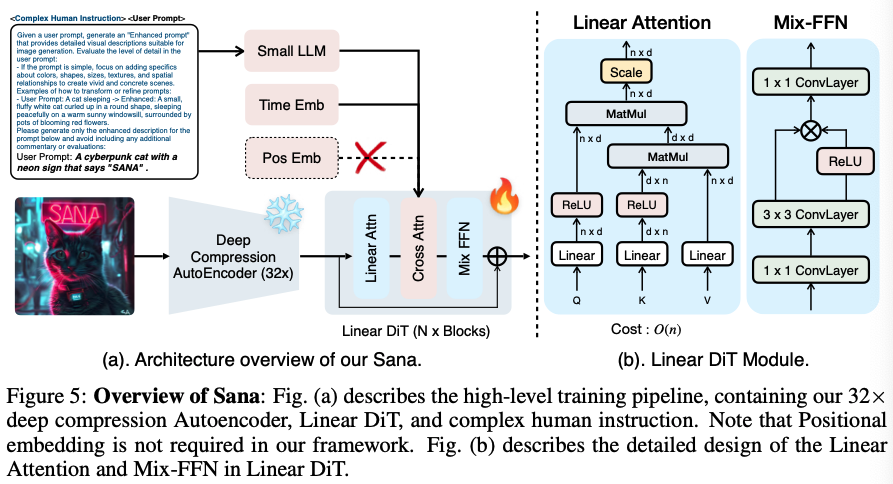
SANA integrates three co-optimized components—a deep compression autoencoder, a Linear Diffusion Transformer (Linear-DiT), and a decoder-only LLM-based text encoder—into a unified Rectified-Flow diffusion pipeline.
Unlike conventional LDMs that loosely connect compression, denoising, and conditioning, SANA treats them as mutually constrained modules that co-reduce token count, memory access, and diffusion step count.
The full pipeline compresses, conditions, and denoises in a 32× latent space with O(N) attention, achieving 4K synthesis in single-digit seconds.
1. Deep Compression Autoencoder (AE-F32C32)
SANA’s autoencoder maps an image
\(\mathbf{x} \in \mathbb{R}^{3 \times H \times W}\)
into a latent grid
Key properties:
- Downsampling factor (F=32) → each dimension reduced 32× (vs 8× in SDXL), giving 1/16 the token count.
- Channel depth (C=32) balances reconstruction quality and token sparsity, achieving rFID = 0.34, PSNR = 29.3 dB at 4K.
- No patch flattening (
P=1): AE performs all spatial compression, keeping diffusion tokens semantically dense. - Multi-stage fine-tuning (512 → 1K → 2K → 4K) with LPIPS + SSIM losses preserves texture fidelity.
- Efficiency gain: at 4K (4096²), only 128×128 = 16 K latent tokens feed the transformer—small enough for linear attention to scale linearly in both FLOPs and memory.
2. Linear Diffusion Transformer (Linear-DiT)
The denoising backbone is a Transformer-only architecture with ReLU linear attention:
\[\text{Attn}(Q,K,V) = \frac{\mathrm{ReLU}(Q)\,[\,(\mathrm{ReLU}(K)^\top V)\,]} {\mathrm{ReLU}(Q)\,[\,(\mathrm{ReLU}(K)^\top \mathbf{1})\,]},\]achieving O(N) complexity in both time and memory.
Each block follows the structure:
LayerNorm → Linear Attention → Mix-FFN → Residual
Mix-FFN merges a 1×1 MLP, a 3×3 depthwise convolution, and a Gated Linear Unit (GLU).
This reintroduces local spatial bias lost in linear attention, removing the need for positional encodings (NoPE design).
Empirically, this yields improved long-range coherence and stability across large image scales.
Additional design notes:
- Kernel fusion (Triton) combines projection, activation, and normalization (≈ +10% runtime gain).
- Depth/width: 28 blocks @ 1152d (SANA-0.6B) or 20 blocks @ 2240d (SANA-1.6B).
- Complexity: Linear in resolution, bounded by memory bandwidth rather than attention scaling.
3. LLM-Based Text Conditioning (Gemma-2 + CHI)
SANA replaces encoder–decoder T5 with Gemma-2, a compact decoder-only LLM trained with instruction following.
Prompts are expanded via Complex Human Instruction (CHI) templates that rewrite under-specified inputs (e.g., “a cat” → “a fluffy white cat curled up by a sunlit window”).
This enhances the contextual grounding of the diffusion model.
Implementation details:
- Extract final-layer decoder states as semantic embeddings.
- Apply RMSNorm + scale 0.01 to stabilize gradients (without it, NaNs occur).
- Keys/values in cross-attention come from Gemma embeddings; queries from latent tokens.
- Improves text-image alignment by ≈ +2 CLIP score and reduces prompt drift at 4K.
4. Flow-Based Denoising with Flow-DPM-Solver
SANA trains under the Rectified-Flow objective:
\[\mathcal{L}_{\text{flow}} = \big\|\,v_\theta(\mathbf{z}_t,t,p) - (\boldsymbol{\epsilon}-\mathbf{x}_0)\,\big\|_2^2,\]predicting velocity instead of noise.
A modified Flow-DPM-Solver adapts DPM-Solver++ with rectified-flow scaling (α → 1−σ), achieving convergence in 14–20 steps—about 2–3× fewer than Euler-based solvers.
Combined with cascade-resolution training, this enables fast 1K–4K synthesis with minimal perceptual degradation.
5. System-Level Efficiency
- INT8 (W8A8) quantization with per-channel scaling for weights & activations → 2.4× speed-up at negligible quality loss.
- CUDA/Triton kernel fusion merges QKV projection, GLU, and quantization stages.
- Latency: 0.37 s @ 1K on RTX 4090 laptop, 5.9 s @ 4K on A100.
- Throughput: ~40× faster than SDXL, ~100× faster than FLUX-Dev.
Results Summary

| Model | Params | Resolution | FID↓ | CLIP↑ | GenEval↑ | 4K Speed (A100) |
|---|---|---|---|---|---|---|
| FLUX-dev | 12 B | 4K | 5.7 | 28.7 | 0.66 | 1023 s |
| SANA-1.6B | 1.6 B | 4K | 5.8 | 28.6 | 0.66 | 5.9 s |
| SANA-0.6B | 0.6 B | 1–4K | 5.81 | 28.36 | 0.64 | 9.6 s |
SANA matches the quality of 12B-parameter models
while being over 100× faster at 4K resolution.
Limitations
- Training still requires large-scale compute despite architectural efficiency.
- Mild blur at ultra-high (>8K) resolutions from linear attention approximation.
- Compression limits extreme zoom or detailed inpainting.
- Lacks fine-grained region-based or controllable editing interface.
Takeaways
SANA represents a paradigm shift in diffusion model design —
from parameter scaling to architectural intelligence.
Through deep compression, linear attention, and LLM-based conditioning,
it delivers real-time, high-fidelity text-to-image generation.
Its innovations also resonate with 3D vision and Gaussian rendering trends:
- Flow-based denoising parallels single-step 3D refinement (e.g., DIFIX3D+).
- Linear attention could enable scalable 2D–3D latent fusion in future rendering pipelines.
SANA thus stands as a blueprint for next-generation efficient diffusion systems.